ETL Pipeline
提取、转换和加载(ETL)框架是检索增强生成(RAG)用例中数据处理的支柱。
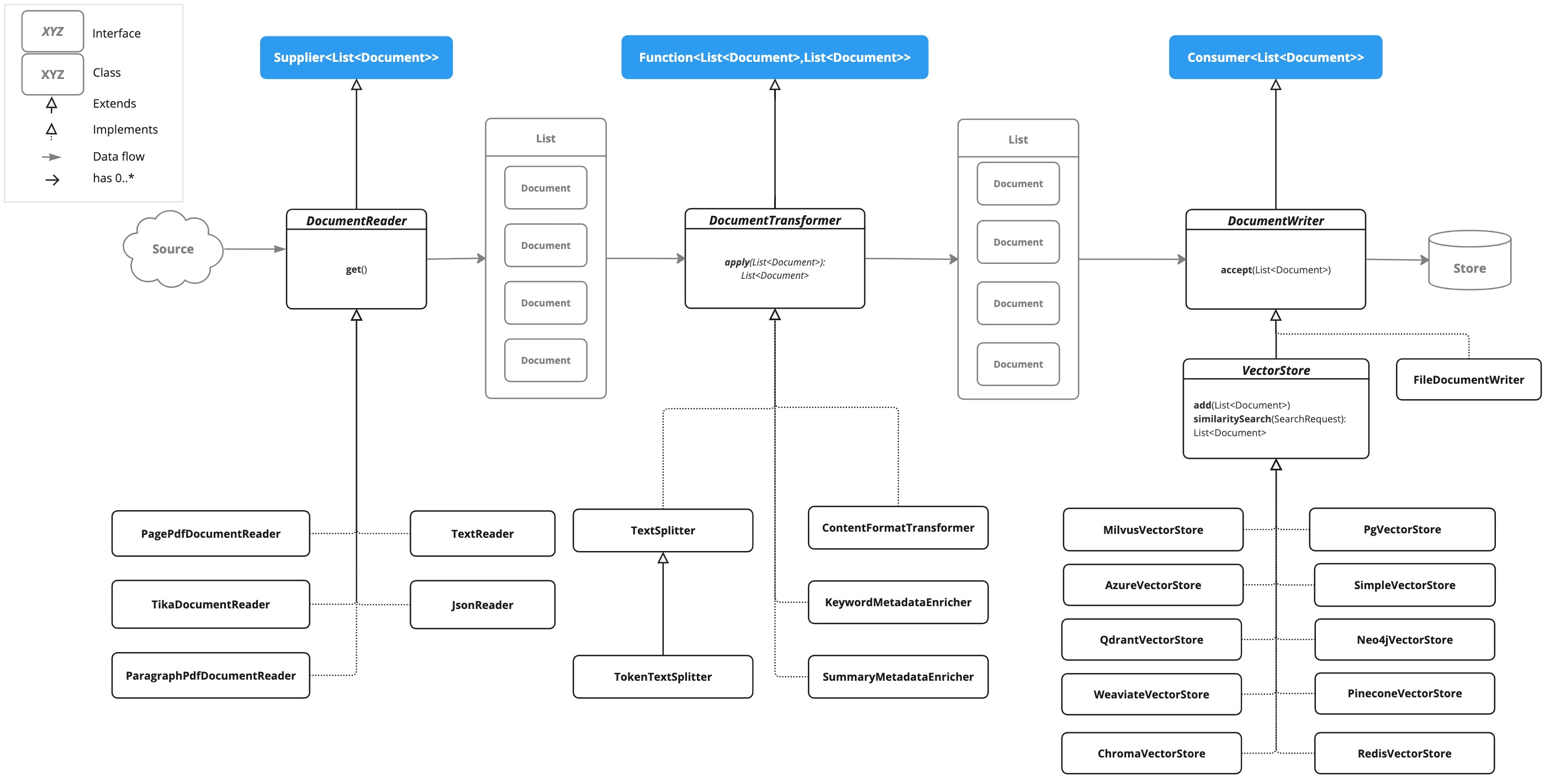
ETL管道 orchestrates 从原始数据源到结构化向量存储的流程,确保数据以最佳格式存储以供AI模型检索。
RAG用例是通过从数据体中检索相关信息来增强生成模型的能力,从而提高生成输出的质量和相关性的文本。
API 概述
ETL管道的三个主要组件如下:
-
DocumentReader实现了Supplier<List<Document>> -
DocumentTransformer实现了Function<List<Document>, List<Document>> -
DocumentWriter实现了Consumer<List<Document>>
Document 类包含文本和元数据,并通过 DocumentReader 从PDF、文本文件和其他文档类型创建。
要构建一个简单的ETL管道,您可以链式连接每种类型的实例。

假设我们有以下三种ETL类型的实例
-
PagePdfDocumentReader是DocumentReader的实现 -
TokenTextSplitter是DocumentTransformer的实现 -
VectorStore是DocumentWriter的实现
要执行将数据基本加载到向量数据库以供与检索增强生成模式一起使用,使用以下代码。
vectorStore.accept(tokenTextSplitter.apply(pdfReader.get()));入门指南
要开始创建Spring AI RAG应用程序,请按照以下步骤进行:
-
下载最新的 Spring CLI Release 并按照 安装说明 进行操作。
-
要创建一个简单的基于OpenAI的应用程序,请使用以下命令:
spring boot new --from ai-rag --name myrag -
参考生成的
README.md文件,了解如何获取OpenAI API密钥并运行您的第一个AI RAG应用程序。
ETL接口和实现
ETL管道由以下接口和实现组成。详细的ETL类图在ETL类图部分显示。
DocumentReader
提供来自不同来源的文档源。
public interface DocumentReader extends Supplier<List<Document>> {
}JsonReader
JsonReader 解析JSON格式的文档。
示例:
@Component
public class MyAiApp {
@Value("classpath:bikes.json") // 这是要加载的json文档
private Resource resource;
List<Document> loadJsonAsDocuments() {
JsonReader jsonReader = new JsonReader(resource, "description");
return jsonReader.get();
}
}TextReader
TextReader 处理纯文本文档。
示例:
@Component
public class MyTextReader {
@Value("classpath:text-source.txt") // 这是要加载的文本文档
private Resource resource;
List<Document> loadText() {
TextReader textReader = new TextReader(resource);
textReader.getCustomMetadata().put("filename", "text-source.txt");
return textReader.get();
}
}PagePdfDocumentReader
PagePdfDocumentReader 使用Apache PdfBox库解析PDF文档。
示例:
@Component
public class MyPagePdfDocumentReader {
List<Document> getDocsFromPdf() {
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader("classpath:/sample1.pdf",
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.withPagesPerDocument(1)
.build());
return pdfReader.get();
}
}ParagraphPdfDocumentReader
ParagraphPdfDocumentReader 使用PDF目录(如目录)信息来将输入PDF分割为文本段落,并输出每个段落一个Document。注意:并非所有PDF文档都包含PDF目录。
示例:
@Component
public class MyPagePdfDocumentReader {
List<Document> getDocsFromPdfwithCatalog() {
new ParagraphPdfDocumentReader("classpath:/sample1.pdf",
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.withPagesPerDocument(1)
.build());
return pdfReader.get();
}
}TikaDocumentReader
TikaDocumentReader 使用Apache Tika从各种文档格式(如PDF、DOC/DOCX、PPT/PPTX和HTML)中提取文本。有关支持的格式的综合列表,请参阅Tika文档。
示例:
@Component
public class MyTikaDocumentReader {
@Value("classpath:/word-sample.docx") // 这是要加载的word文档
private Resource resource;
List<Document> loadText() {
TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(resourceUri);
return tikaDocumentReader.get();
}
}DocumentTransformer
作为处理工作流程的一部分,对一批文档进行转换。
public interface DocumentTransformer extends Function<List<Document>, List<Document>> {
}文档编写器
管理ETL过程的最后阶段,准备文档以供存储。
public interface DocumentWriter extends Consumer<List<Document>> {
}向量存储
提供与各种向量存储的集成。详细列表请参见向量数据库文档。