Ollama聊天
使用Ollama,您可以在本地运行各种大型语言模型(LLMs)并从中生成文本。Spring AI通过OllamaChatClient支持Ollama文本生成。
自动配置
Spring AI为Ollama Chat Client提供了Spring Boot自动配置。要启用它,请将以下依赖项添加到您项目的Maven pom.xml文件中:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>或者添加到您的Gradle build.gradle构建文件中。
dependencies {
implementation 'org.springframework.ai:spring-ai-ollama-spring-boot-starter'
}| 请参阅依赖管理部分,将Spring AI BOM添加到您的构建文件中。 |
聊天属性
前缀spring.ai.ollama是用来配置到Ollama连接的属性前缀
| 属性 | 描述 | 默认值 |
|---|---|---|
|
spring.ai.ollama.base-url |
Ollama API服务器运行的基本URL。 |
前缀spring.ai.ollama.chat.options是用来配置Ollama聊天客户端实现的属性前缀
这些options属性基于Ollama有效参数和数值以及Ollama类型。默认值基于:Ollama类型默认值。 |
| 属性 | 描述 | 默认 |
|---|---|---|
|
spring.ai.ollama.chat.enabled |
启用Ollama聊天客户端。 |
true |
|
spring.ai.ollama.chat.options.model |
要使用的支持的模型的名称。 |
mistral |
|
spring.ai.ollama.chat.options.numa |
是否使用NUMA。 |
false |
|
spring.ai.ollama.chat.options.num-ctx |
设置用于生成下一个标记的上下文窗口的大小。 |
2048 |
|
spring.ai.ollama.chat.options.num-batch |
??? |
512 |
|
spring.ai.ollama.chat.options.num-gqa |
变换器层中GQA组的数量。某些模型需要此选项,例如,llama2:70b的值为8。 |
1 |
|
spring.ai.ollama.chat.options.num-gpu |
要发送到GPU的层数。在macOS上,默认值为1以启用metal支持,为0以禁用。此处的1表示应动态设置NumGPU |
-1 |
|
spring.ai.ollama.chat.options.top-k |
与top-p一起使用。较高的值(例如0.95)会导致更多样化的文本,而较低的值(例如0.5)会生成更加专注和保守的文本。 |
0.9 |
|
spring.ai.ollama.chat.options.tfs-z |
使用Tail-free sampling降低对输出中不太可能的令牌的影响。较高的值(例如2.0)会更有效地降低影响,而1.0的值会禁用此设置。 |
1.0 |
|
spring.ai.ollama.chat.options.typical-p |
??? |
1.0 |
|
spring.ai.ollama.chat.options.repeat-last-n |
设置模型向后查看的距离,以防止重复。(默认值:64,0=禁用,-1=num_ctx) |
64 |
|
spring.ai.ollama.chat.options.temperature |
模型的温度。增大温度会使模型回答更具创造性。 |
0.8 |
|
spring.ai.ollama.chat.options.repeat-penalty |
设置如何惩罚重复。较高的值(例如1.5)会更强烈地惩罚重复,而较低的值(例如0.9)则更宽容。 |
1.1 |
|
spring.ai.ollama.chat.options.presence-penalty |
??? |
0.0 |
|
spring.ai.ollama.chat.options.frequency-penalty |
??? |
0.0 |
|
spring.ai.ollama.chat.options.mirostat |
启用Mirostat采样以控制perplexity。(默认值:0,0=禁用,1=Mirostat,2=Mirostat 2.0) |
0 |
|
spring.ai.ollama.chat.options.mirostat-tau |
影响算法从生成的文本中快速响应反馈的速度。较低的学习率会导致更慢的调整,而较高的学习率会使算法更加敏感。 |
5.0 |
|
spring.ai.ollama.chat.options.mirostat-eta |
控制输出的相关性和多样性的平衡。较低的值会导致更加聚焦和相关的文本。 |
0.1 |
|
spring.ai.ollama.chat.options.penalize-newline |
??? |
true |
|
spring.ai.ollama.chat.options.stop |
设置要使用的停止序列。当遇到此模式时,LLM将停止生成文本并返回。可以通过在模型文件中指定多个单独的停止参数来设置多个停止模式。 |
- |
| chat选项列表正在审核中。这个问题将追踪进展。 |
所有以spring.ai.ollama.chat.options为前缀的属性都可以通过在Prompt调用中添加特定于请求的Chat Options来在运行时重写。 |
聊天选项
OllamaOptions.java 提供了模型配置,例如要使用的模型、温度等。
在启动时,可以通过 OllamaChatClient(api, options) 构造函数或 spring.ai.ollama.chat.options.* 属性来配置默认选项。
在运行时,您可以通过向 Prompt 调用添加新的、针对请求的特定选项来覆盖默认选项。例如,要为特定请求覆盖默认模型和温度:
ChatResponse response = chatClient.call(
new Prompt(
"生成5个著名海盗的名字。",
OllamaOptions.create()
.withModel("llama2")
.withTemperature(0.4)
));| 除了特定于模型的 OllamaOptions,您还可以使用可移植的 ChatOptions 实例,通过 ChatOptionsBuilder#builder() 创建。 |
示例控制器(自动配置)
创建 一个新的 Spring Boot 项目,并将 spring-ai-openai-spring-boot-starter 添加到您的 pom(或 gradle)依赖项中。
在 src/main/resources 目录下添加一个 application.properties 文件,以启用并配置 OpenAi Chat 客户端:
spring.ai.ollama.base-url=http://localhost:11434
spring.ai.ollama.chat.options.model=mistral
spring.ai.ollama.chat.options.temperature=0.7用您的 Ollama 服务器 URL 替换 base-url。 |
这将创建一个可以注入到您的类中的 OllamaChatClient 实现。这里是一个简单的 @Controller 类示例,用于使用聊天客户端生成文本:
@RestController
public class ChatController {
private final OllamaChatClient chatClient;
@Autowired
public ChatController(OllamaChatClient chatClient) {
this.chatClient = chatClient;
}
@GetMapping("/ai/generate")
public Map generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("generation", chatClient.call(message));
}
@GetMapping("/ai/generateStream")
public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
Prompt prompt = new Prompt(new UserMessage(message));
return chatClient.stream(prompt);
}
}手动配置
如果您不想使用Spring Boot自动配置,可以在应用程序中手动配置OllamaChatClient。 OllamaChatClient 实现了ChatClient 和 StreamingChatClient 并使用 低级 OpenAiApi 客户端 连接到 Ollama 服务。
要使用它,请将spring-ai-ollama依赖项添加到项目的 Maven pom.xml 文件中:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama</artifactId>
</dependency>或者添加到您的 Gradle build.gradle 文件中。
dependencies {
implementation 'org.springframework.ai:spring-ai-ollama'
}| 参考依赖管理部分将 Spring AI BOM 添加到您的构建文件中。 |
spring-ai-ollama 依赖项还提供对 OllamaEmbeddingClient 的访问。有关 OllamaEmbeddingClient 的更多信息,请参阅Ollama Embedding Client 部分。 |
接下来,创建一个 OllamaChatClient 实例并使用它进行文本生成请求:
var ollamaApi = new OllamaApi();
var chatClient = new OllamaChatClient(ollamaApi).withModel(MODEL)
.withDefaultOptions(OllamaOptions.create()
.withModel(OllamaOptions.DEFAULT_MODEL)
.withTemperature(0.9f));
ChatResponse response = chatClient.call(
new Prompt("生成5个著名海盗的姓名。"));
// 或者使用流式响应
Flux<ChatResponse> response = chatClient.stream(
new Prompt("生成5个著名海盗的姓名。"));OllamaOptions 提供了所有聊天请求的配置信息。
低级 OpenAiApi 客户端
OllamaApi 提供了轻量级的 Java 客户端用于 Ollama Chat API Ollama Chat Completion API。
以下类图说明了 OllamaApi 的聊天接口和构建模块:
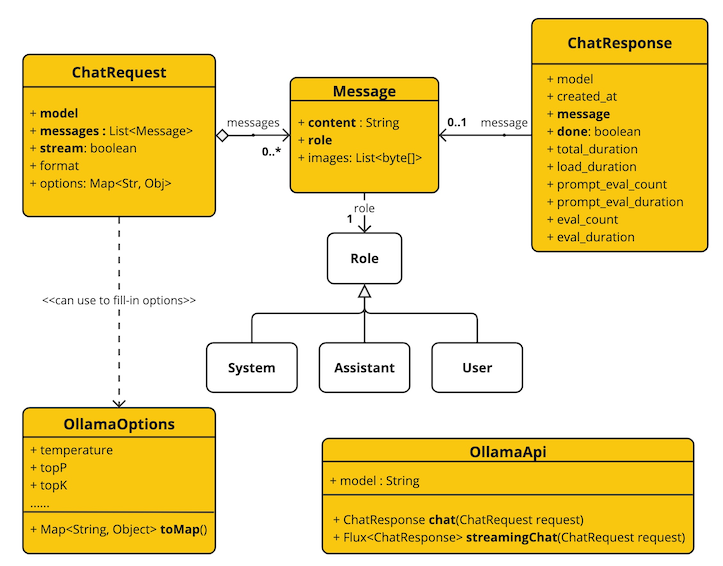
这是如何以编程方式使用 API 的简单代码片段:
OllamaApi ollamaApi =
new OllamaApi("YOUR_HOST:YOUR_PORT");
// 同步请求
var request = ChatRequest.builder("orca-mini")
.withStream(false) // not streaming
.withMessages(List.of(
Message.builder(Role.SYSTEM)
.withContent("你是地理老师。你正在和一名学生交谈。")
.build(),
Message.builder(Role.USER)
.withContent("保加利亚的首都是什么?大小如何?国歌是什么?")
.build()))
.withOptions(OllamaOptions.create().withTemperature(0.9f))
.build();
ChatResponse response = ollamaApi.chat(request);
// 流式请求
var request2 = ChatRequest.builder("orca-mini")
.withStream(true) // streaming
.withMessages(List.of(Message.builder(Role.USER)
.withContent("保加利亚的首都是什么?大小如何?国歌是什么?")
.build()))
.withOptions(OllamaOptions.create().withTemperature(0.9f).toMap())
.build();
Flux<ChatResponse> streamingResponse = ollamaApi.streamingChat(request2);
