课程: 可扩展样式表语言转换
本教程是针对JDK 8编写的。本页面描述的示例和实践不利用后续版本中引入的改进,可能使用已不再可用的技术。
有关Java SE 9及后续版本中更新的语言特性的摘要,请参阅Java语言更改。
有关所有JDK版本的新功能、增强功能和已删除或弃用选项的信息,请参阅JDK发行说明。
从任意数据结构生成XML
本部分使用XSLT将任意数据结构转换为XML。
以下是该过程的概要:
-
修改现有的读取数据的程序,使其生成SAX事件。(无论该程序是真正的解析器还是仅仅是某种数据过滤器,在此刻都是无关紧要的)。
-
使用SAX "解析器"构建用于转换的SAXSource。
-
使用上一个练习中创建的相同StreamResult对象来显示结果。(但请注意,您也可以轻松创建一个DOMResult对象来在内存中创建DOM)。
-
使用转换器对象将源连接到结果,进行转换。
首先,您需要一个要转换的数据集和一个能够读取数据的程序。下面的两个部分创建了一个简单的数据文件和一个读取它的程序。
创建一个简单的文件
此示例使用地址簿的数据集PersonalAddressBook.ldif。如果您还没有这样做,请下载XSLT示例并将其解压缩到install-dir/jaxp-1_4_2-release-date/samples目录中。解压缩XSLT示例后,该文件位于xslt/data目录中。
下面的图 显示了所创建的地址簿条目。
图 地址簿条目
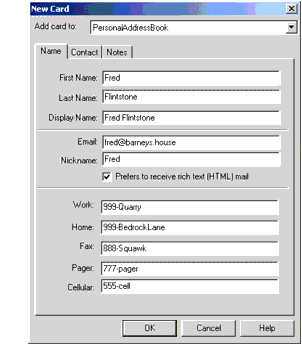
导出地址簿会产生一个类似下面的文件。我们关心的文件部分以粗体显示。
dn: cn=Fred Flintstone,mail=fred@barneys.house modifytimestamp: 20010409210816Z cn: Fred Flintstone xmozillanickname: Fred mail: Fred@barneys.house xmozillausehtmlmail: TRUE givenname: Fred sn: Flintstone telephonenumber: 999-Quarry homephone: 999-BedrockLane facsimiletelephonenumber: 888-Squawk pagerphone: 777-pager cellphone: 555-cell xmozillaanyphone: 999-Quarry objectclass: top objectclass: person
请注意,文件的每一行都包含一个变量名,一个冒号和一个空格,后面跟着该变量的值。变量sn包含人的姓(姓氏),变量cn包含地址簿条目中的DisplayName字段。
创建一个简单的解析器
下一步是创建一个解析数据的程序。
注意 - 本节讨论的代码位于AddressBookReader01.java中,该文件可以在你解压缩XSLT examples后,在install-dir/jaxp-1_4_2-release-date/samples目录下找到。
下面显示了该程序的文本。这是一个非常简单的程序,甚至不会循环处理多个条目,因为毕竟它只是一个演示。
import java.io.*;
public class AddressBookReader01 {
public static void main(String argv[]) {
// 检查参数
if (argv.length != 1) {
System.err.println("用法: java AddressBookReader01 filename");
System.exit (1);
}
String filename = argv[0];
File f = new File(filename);
AddressBookReader01 reader = new AddressBookReader01();
reader.parse(f);
}
// 解析输入文件
public void parse(File f) {
try {
// 获取文件的高效读取器
FileReader r = new FileReader(f);
BufferedReader br = new BufferedReader(r);
// 读取文件并显示其内容。
String line = br.readLine();
while (null != (line = br.readLine())) {
if (line.startsWith("xmozillanickname: "))
break;
}
output("昵称", "xmozillanickname", line);
line = br.readLine();
output("邮箱", "mail", line);
line = br.readLine();
output("HTML", "xmozillausehtmlmail", line);
line = br.readLine();
output("名字","givenname", line);
line = br.readLine();
output("姓氏", "sn", line);
line = br.readLine();
output("工作电话", "telephonenumber", line);
line = br.readLine();
output("家庭电话", "homephone", line);
line = br.readLine();
output("传真", "facsimiletelephonenumber", line);
line = br.readLine();
output("传呼机", "pagerphone", line);
line = br.readLine();
output("手机", "cellphone", line);
}
catch (Exception e) {
e.printStackTrace();
}
}
}
该程序包含三个方法:
- main
-
main方法从命令行获取文件名,创建一个解析器的实例,并将其设置为解析文件的工作。当我们将程序转换为SAX解析器时,该方法将消失。(这是将解析代码放入单独方法中的一个原因)。
- parse
-
此方法对主程序发送的File对象进行操作。如您所见,它非常简单。唯一考虑到效率的地方是使用了一个BufferedReader,当您开始操作大文件时,这一点可能变得重要。
- output
-
输出方法包含了一行的结构逻辑。它接收三个参数。第一个参数给出了要显示的名称,以便可以输出html作为变量名,而不是xmozillausehtmlmail。第二个参数给出了存储在文件中的变量名(xmozillausehtmlmail)。第三个参数给出了包含数据的行。然后,该程序从行的开头删除变量名,并输出所需的名称和数据。
运行AddressBookReader01示例
- 导航到samples目录。
% cd install-dir/jaxp-1_4_2-release-date/samples.
-
点击此链接下载XSLT示例并将其解压缩到install-dir/jaxp-1_4_2-release-date/samples目录中。 - 导航到xslt目录。
cd xslt
- 编译AddressBookReader01示例。
输入以下命令:
% javac AddressBookReader01.java
- 在数据文件上运行AddressBookReader01示例。
在下面的情况下,AddressBookReader01在上面显示的PersonalAddressBook.ldif文件上运行,在解压缩示例包后在xslt/data目录中找到。
% java AddressBookReader01 data/PersonalAddressBook.ldif
你将看到以下输出:
昵称:Fred 电子邮件:Fred@barneys.house html:TRUE 名字:Fred 姓氏:Flintstone 工作:999-Quarry 住宅:999-BedrockLane 传真:888-Squawk 寻呼机:777-pager 手机:555-cell
这比创建一个简单文件中显示的文件更易读。
创建生成SAX事件的解析器
本节展示如何使解析器生成SAX事件,以便您可以将其用作XSLT转换中SAXSource对象的基础。
注意:本节中讨论的代码在AddressBookReader02.java中,解压缩XSLT示例到install-dir/jaxp-1_4_2-release-date/samples目录后,在xslt目录中找到AddressBookReader02.java。 AddressBookReader02.java是从AddressBookReader01.java改编的,因此只讨论两个示例之间的代码差异。
AddressBookReader02需要以下突出显示的类,AddressBookReader01中未使用这些类。
import java.io.*; import org.xml.sax.*; import org.xml.sax.helpers.AttributesImpl;
该应用程序还扩展了XmlReader。此更改将应用程序转换为生成适当SAX事件的解析器。
public class AddressBookReader02 implements XMLReader { /* ... */ }
与AddressBookReader01示例不同,该应用程序没有main方法。
以下全局变量将在本节后面使用:
public class AddressBookReader02 implements XMLReader {
ContentHandler handler;
String nsu = "";
Attributes atts = new AttributesImpl();
String rootElement = "addressbook";
String indent = "\n ";
// ...
}
SAX ContentHandler是将接收解析器生成的SAX事件的对象。为了使应用程序成为XmlReader,应用程序定义了setContentHandler方法。当调用setContentHandler时,handler变量将保存对被发送对象的引用。
当解析器生成SAX元素事件时,它将需要提供命名空间和属性信息。由于这是一个简单的应用程序,它为这两个值定义了null。
该应用程序还为数据结构(addressbook)定义了一个根元素,并设置了一个缩进字符串以提高输出的可读性。
此外,解析方法被修改为将InputSource(而不是File)作为参数,并处理可能引发的异常:
public void parse(InputSource input) throws IOException, SAXException
现在,不再像在AddressBookReader01中那样创建一个新的FileReader实例,而是将读取器封装在InputSource对象中:
try {
java.io.Reader r = input.getCharacterStream();
BufferedReader Br = new BufferedReader(r);
// ...
}
注意:下一节将展示如何创建输入源对象以及放入其中的内容实际上将是一个缓冲读取器。但是,AddressBookReader可能会被其他人在不同的地方使用。这一步确保无论您获得哪个读取器,处理都将高效。
下一步是修改解析方法以生成文档和根元素的SAX事件。以下突出显示的代码实现了这一点:
public void parse(InputSource input) {
try {
// ...
String line = br.readLine();
while (null != (line = br.readLine())) {
if (line.startsWith("xmozillanickname: "))
break;
}
if (handler == null) {
throw new SAXException("No content handler");
}
handler.startDocument();
handler.startElement(nsu, rootElement, rootElement, atts);
output("nickname", "xmozillanickname", line);
// ...
output("cell", "cellphone", line);
handler.ignorableWhitespace("\n".toCharArray(),
0, // start index
1 // length
);
handler.endElement(nsu, rootElement, rootElement);
handler.endDocument();
}
catch (Exception e) {
// ...
}
}
在这里,应用程序检查解析器是否正确配置了ContentHandler。(对于这个应用程序,我们不关心其他任何内容)。然后,它生成文档和根元素的开始事件,并通过发送根元素的结束事件和文档的结束事件完成。
此时有两个值得注意的地方:
-
尚未发送setDocumentLocator事件,因为它是可选的。如果重要的话,该事件将在startDocument事件之前立即发送。
-
在根元素结束之前生成了一个ignorableWhitespace事件。这也是可选的,但它极大地提高了输出的可读性,很快就会看到。(在这种情况下,空格由一个换行符组成,以与字符方法相同的方式发送:作为字符数组,一个起始索引和一个长度)。
现在,SAX事件正在为文档和根元素生成,下一步是修改输出方法,为每个数据项生成适当的元素事件。删除调用System.out.println(name + ": " + text)并添加下面突出显示的代码即可实现:
void output(String name, String prefix, String line)
throws SAXException {
int startIndex =
prefix.length() + 2; // 2=length of ": "
String text = line.substring(startIndex);
int textLength = line.length() - startIndex;
handler.ignorableWhitespace (indent.toCharArray(),
0, // start index
indent.length()
);
handler.startElement(nsu, name, name /*"qName"*/, atts);
handler.characters(line.toCharArray(),
startIndex,
textLength;
);
handler.endElement(nsu, name, name);
}
由于ContentHandler方法可以向解析器发送SAXExceptions,所以解析器必须准备好处理它们。在这种情况下,不会出现任何异常,因此如果出现任何异常,应用程序将允许失败。
然后计算数据的长度,再次生成一些可忽略的空格以提高可读性。在这种情况下,只有一个层级的数据,所以我们可以使用一个固定缩进的字符串。(如果数据更有结构,我们将不得不根据数据的嵌套计算缩进的空间)。
注意 - 缩进字符串对数据没有影响,但会使输出更容易阅读。如果没有该字符串,所有元素将被连接在一起:
<addressbook> <nickname>Fred</nickname> <email>...
接下来,以下方法配置解析器以接收其生成的事件的ContentHandler:
void output(String name, String prefix, String line)
throws SAXException {
// ...
}
// 允许应用程序注册内容事件处理程序。
public void setContentHandler(ContentHandler handler) {
this.handler = handler;
}
// 返回当前的内容处理程序。
public ContentHandler getContentHandler() {
return this.handler;
}
为了满足XmlReader接口的要求,还必须实现几个其他方法。为了这个示例的目的,为所有这些方法生成了空方法。然而,一个实际的应用程序需要实现错误处理程序方法,以生成更健壮的应用程序。但是对于这个示例,以下代码为它们生成了空方法:
// 允许应用程序注册错误事件处理程序。
public void setErrorHandler(ErrorHandler handler) { }
// 返回当前的错误处理程序。
public ErrorHandler getErrorHandler() {
return null;
}
然后,以下代码为XmlReader接口的其余部分生成了空方法。(其中大多数对于真实的SAX解析器非常有价值,但对于像这样的数据转换应用程序则没有太大关系)。
// 从系统标识符(URI)解析XML文档。
public void parse(String systemId) throws IOException, SAXException
{ }
// 返回当前的DTD处理程序。
public DTDHandler getDTDHandler() { return null; }
// 返回当前的实体解析器。
public EntityResolver getEntityResolver() { return null; }
// 允许应用程序注册实体解析器。
public void setEntityResolver(EntityResolver resolver) { }
// 允许应用程序注册DTD事件处理程序。
public void setDTDHandler(DTDHandler handler) { }
// 查找属性的值。
public Object getProperty(String name) { return null; }
// 设置属性的值。
public void setProperty(String name, Object value) { }
// 设置特性的状态。
public void setFeature(String name, boolean value) { }
// 查找特性的值。
public boolean getFeature(String name) { return false; }
现在你有一个可以用来生成SAX事件的解析器。在下一节中,你将使用它来构造一个SAX源对象,以将数据转换为XML。
使用解析器作为SAXSource
给定一个作为事件源的SAX解析器,你可以构造一个转换器来生成结果。在本节中,TransformerApp将更新为生成流输出结果,尽管它也可以很容易地生成DOM结果。
注意 - 注:本节讨论的代码位于TransformationApp03.java中,可以在解压XSLT示例后在install-dir/jaxp-1_4_2-release-date/samples目录中找到。
首先,TransformationApp03与TransformationApp02在构造SAXSource对象时需要导入的类不同。下面的代码突出显示了这些类。这时不再需要DOM类,因此它们被丢弃了,但是保留它们不会造成任何损害。
import org.xml.sax.SAXException; import org.xml.sax.SAXParseException; import org.xml.sax.ContentHandler; import org.xml.sax.InputSource; import javax.xml.transform.sax.SAXSource; import javax.xml.transform.stream.StreamResult;
接下来,不再创建DOM DocumentBuilderFactory实例,而是创建一个SAX解析器,它是AddressBookReader的一个实例:
public class TransformationApp03 {
static Document document;
public static void main(String argv[]) {
// ...
// 创建sax解析器。
AddressBookReader saxReader = new AddressBookReader();
try {
File f = new File(argv[0]);
// ...
}
// ...
}
}
然后,以下突出显示的代码构造了一个SAXSource对象
// 用于输出的Transformer // ... Transformer transformer = tFactory.newTransformer(); // 使用解析器作为SAX输入源 FileReader fr = new FileReader(f); BufferedReader br = new BufferedReader(fr); InputSource inputSource = new InputSource(br); SAXSource source = new SAXSource(saxReader, inputSource); StreamResult result = new StreamResult(System.out); transformer.transform(source, result);
在这里,TransformationApp03构造了一个缓冲读取器(如前所述),并将其封装在一个输入源对象中。然后,它创建了一个SAXSource对象,将读取器和InputSource对象传递给它,并将其传递给转换器。
当应用程序运行时,转换器将自身配置为SAX解析器(AddressBookReader)的ContentHandler,并告诉解析器对inputSource对象进行操作。解析器生成的事件然后传递给转换器,后者会进行适当的操作,并将数据传递给结果对象。
最后,TransformationApp03不会生成异常,因此TransformationApp02中看到的异常处理代码不再存在。
运行TransformationApp03示例
- 导航到samples目录。
% cd install-dir/jaxp-1_4_2-release-date/samples.
-
点击此链接下载XSLT示例文件,并将其解压到install-dir/jaxp-1_4_2-release-date/samples目录中。 - 导航到xslt目录。
cd xslt
- 编译TransformationApp03示例。
输入以下命令:
% javac TransformationApp03.java
- 在要转换为XML的数据文件上运行TransformationApp03示例。
在下面的例子中,将在解压示例包后在xslt/data目录中找到的PersonalAddressBook.ldif文件上运行TransformationApp03。
% java TransformationApp03 data/PersonalAddressBook.ldif
您将看到以下输出:
<?xml version="1.0" encoding="UTF-8"?> <addressbook> <nickname>Fred</nickname> <email>Fred@barneys.house</email> <html>TRUE</html> <firstname>Fred</firstname> <lastname>Flintstone</lastname> <work>999-Quarry</work> <home>999-BedrockLane</home> <fax>888-Squawk</fax> <pager>777-pager</pager> <cell>555-cell</cell> </addressbook>正如您所看到的,LDIF格式文件PersonalAddressBook已转换为XML!