课程:处理文本
章节:检测文本边界
Java教程是针对JDK 8编写的。本页面中描述的示例和实践不利用后续版本引入的改进,并且可能使用不再可用的技术。
有关Java SE 9及其后续版本中更新的语言特性的概述,请参阅Java语言更改。
有关所有JDK版本的新功能、增强功能和已删除或已弃用选项的信息,请参阅JDK发布说明。
字符边界
如果您的应用程序允许最终用户突出显示单个字符或逐个字符移动文本光标,您需要定位字符边界。要创建一个定位字符边界的BreakIterator,可以调用getCharacterInstance方法,如下所示:
BreakIterator characterIterator =
BreakIterator.getCharacterInstance(currentLocale);
这种类型的BreakIterator可以检测用户字符之间的边界,而不仅仅是Unicode字符。
一个用户字符可能由多个Unicode字符组成。例如,用户字符ü可以由组合Unicode字符\u0075 (u)和\u00a8 (¨)构成。这不是最好的例子,因为字符ü也可以用单个Unicode字符\u00fc表示。我们将利用阿拉伯语来举一个更实际的例子。
在阿拉伯语中,房子的单词为:
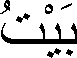
这个单词包含三个用户字符,但它由以下六个Unicode字符组成:
String house = "\u0628" + "\u064e" + "\u064a" + "\u0652" + "\u067a" + "\u064f";
在house字符串中,位于位置1、3和5的Unicode字符是变音符号。阿拉伯语需要变音符号,因为它们可以改变单词的意义。这个例子中的变音符号是非间距字符,因为它们出现在基础字符上方。在阿拉伯语的文字处理程序中,您不能为字符串中的每个Unicode字符在屏幕上移动光标一次。相反,您必须为每个用户字符移动一次光标,这个用户字符可能由多个Unicode字符组成。因此,您必须使用BreakIterator来扫描字符串中的用户字符。
示例程序BreakIteratorDemo创建一个BreakIterator来扫描阿拉伯字符。程序将这个BreakIterator和之前创建的String对象一起传递给一个名为listPositions的方法:
BreakIterator arCharIterator = BreakIterator.getCharacterInstance(
new Locale ("ar","SA"));
listPositions (house, arCharIterator);
listPositions方法使用BreakIterator来定位字符串中的字符边界。注意,BreakIteratorDemo使用setText方法将特定的字符串分配给BreakIterator。程序使用first方法检索第一个字符边界,然后调用next方法,直到返回常量BreakIterator.DONE。该例程的代码如下:
static void listPositions(String target, BreakIterator iterator) {
iterator.setText(target);
int boundary = iterator.first();
while (boundary != BreakIterator.DONE) {
System.out.println (boundary);
boundary = iterator.next();
}
}
listPositions方法为字符串house中的用户字符打印出以下边界位置。请注意,变音符号的位置(1、3、5)没有列出:
0 2 4 6